I am a full stack developer, designer, and illustrator; Studied at Rutgers University with a double major in Computer Science and Finance;
Have interest in so many things that I want to explore them all!
Skill Set :
Programming Language : Java, Python, C, Latex, C#, SQL, JavaScript, TypeScript, HTML, CSS
Frameworks : .NET Core, Angular, Angular-Cli, Entity Framework Core, ASP.NET Core Web API, Bootstrap

Hello and Welcome to my personal website!
Here you will see some of my game developments and previous project explained in details.
Feel free to leave a comment or suggestions by clicking the Comment Section on the NavBar on the top ;)
Projects
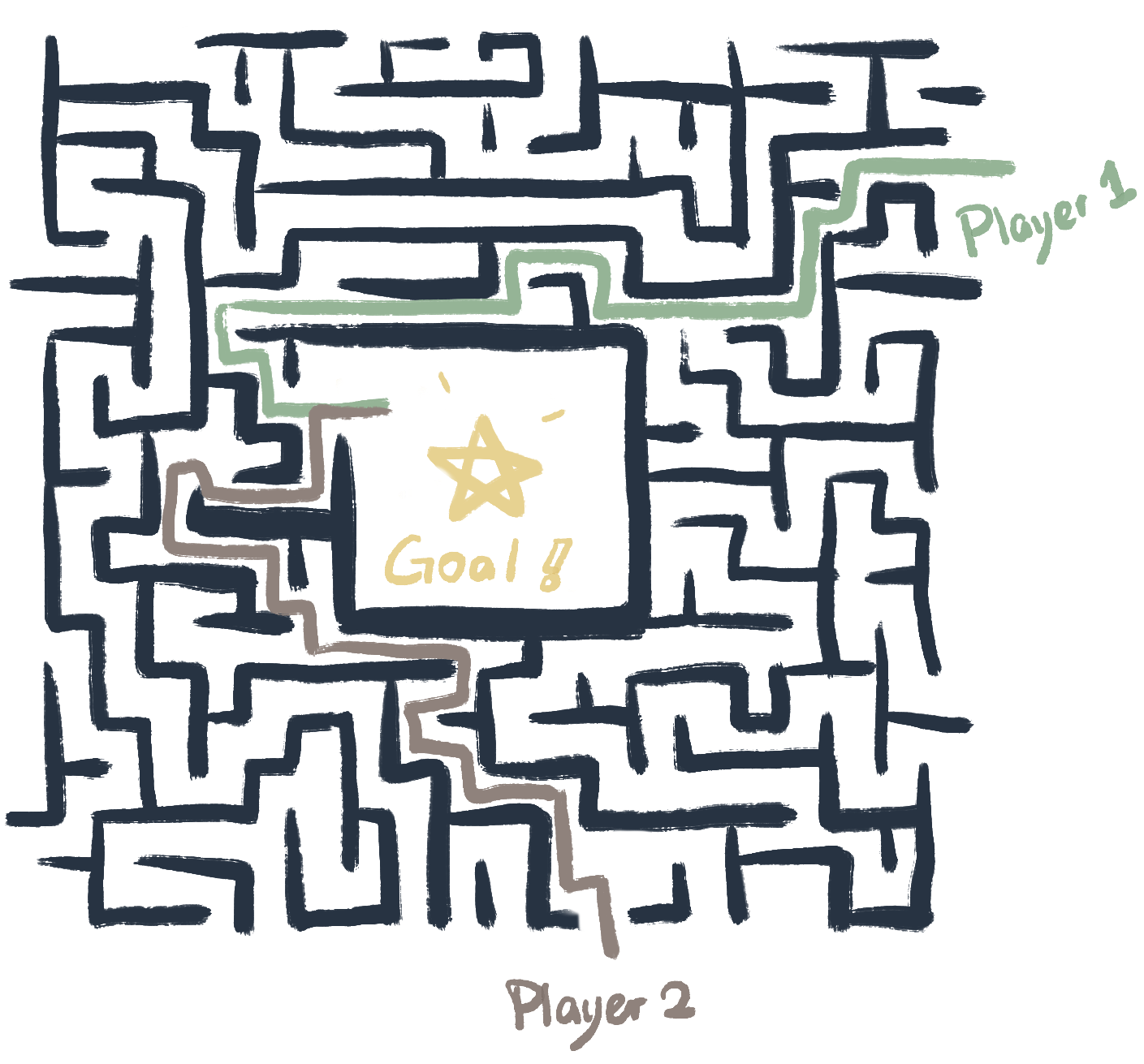
Auto-Generated Maze Game for 2 players!
Auto generating maze and random player's positions and one final position to get, whoever meet the final goal first will be the WINNER~
This game is implementing using socket.io for client-server communication;
Progamming Language : Html, CSS and Javascript (Launching soooooon!)
Multiple Model Ensemble for Cross-Lingual Question Answering
As the amount of information available to the average person has increased dramatically in recent years, much progress has been made in the field of automated question answering systems. Much of this effort has gone into monolingual question answering, especially in English, due to the overwhelming presence of English-language information present on the web. It can be challenging to apply these results to languages with less readily accessible material, imposing barriers on global communities trying to find relevant information.
In this project, we propose a novel ensemble method for utilizing large English corpora for answering questions in a variety of languages. We find that, when dealing with multilingual queries and an English only context corpus, query translation and late-interaction retrieval outperforms dense passage retrieval with a multilingual encoder.

Imputation of Missing Financial Data
Missing data is a common practical problem often encountered in data collection. It is prevalent in virtually all areas and the finance industry is one of the most affected. In fact, in asset pricing studies, missing covariates like firm characteristics are frequently observed.
In this project, we aim to find a better approach for imputing financial data via machine learning techniques, so that more complete data can be used for further analysis. To be more specific, we are going to use firm characteristics as our imputation target. Some important characteristics include book-to-market (B2M), operating profitability (OP), investment (INV), and leverage (LEV).
We mainly try four different algorithms to impute missing data in these firm characteristics: Generative Adversarial Imputation Nets (GAIN), Variational Autoencoder (VAE), KNN impute algorithm, Random Forest Imputation (MissForest).
Self-Supervised Learning Methods on Room Type Classification
As the world increasingly embraces smart home technologies and automation, the need for accurate room type classification algorithms has become paramount. These algorithms are instrumental in enhancing home automation, facilitating robot navigation, fortifying security systems, and other AI applications. Our motivation to address this challenge lies in the potential improvements these systems could bring to various domestic and commercial applications, improving lives and operational efficiency.
The problem at hand involves developing a selfsupervised learning model that can accurately classify different room types in a dynamic domestic environment using visual input. Such a model should account for factors like furniture repositioning, lighting changes, and other environmental alterations affecting room appearances. The input to our algorithm is an image, and we leverage pre-trained self-supervised learning models like SimCLR, MAE, and DINO v2 to output a predicted room type, such as a living room, kitchen, bedroom, or bathroom.
Supervised learning models currently in use require extensive labeled datasets, which can be costly, timeconsuming, and subject to human error. Additionally, these models struggle to generalize their learning to unseen environments. To counter these challenges, our focus is on self-supervised learning, where models learn from unlabeled data, creating useful representations for downstream tasks. We aim to utilize these representations to accurately classify room types in a dynamic environment.
A* Algorithm Implementation and Report
Problem stated : Finding the shortest possible path from a START (A) postion to a TARGET (T) position with randomly generated blocks
Algorithms implemented : Forward A* Tracking VS. Backward A* Tracking, Heuristics in the Adapted A* Tracking
Report : Mainly comparing all three algorithms when facing the problem of finding the shortest path. Explaining reason such as "Why Repeated Forward A* with Adaptive A* is sometimes faster than Repeated Forward A* with A* and sometime isn't" based on our research and implementation.
Movie Shop Single Page Application
This SPA is use to shop for movies, this is a full stack application where I use Angular for Frontend and .NET framework and C# for Backend and implemented API to connect in between. Having a relational database using Microsoft AQL server to hold the database and generating SQL queries using LINQ from the Backend
More details : features of this project includes
1). User login/register/JWT Authenication
2). Users have own categories of movies sorted by favorited and purchased
3). Movies can be displayed by different genres
4). Pagination
Github Source code are below~